VIBES
Variational Inference for Bayesian Networks
[Sourceforge project page]
John Winn, January 2004
|
VIBESVariational Inference for Bayesian Networks |
[Sourceforge project page] John Winn, January 2004 |
| Overview | Tutorial | Examples | Help |
 Contents
Contents

5. Inference in the Gaussian mixture modelWith the mixture of Gaussians model complete, inference can once again proceed
automatically by pressing the Note: Although variational inference is deterministic, VIBES uses a random initialisation each time inference is performed (unless a random seed is set or initial values are provided). It is, therefore, possible that the optimisation may be caught in a local maximum and you may get different results than given in this tutorial. If this occurs, you can simply repeat inference until an initialisation occurs which avoids local maxima.
The means of the retained components can be inspected by double-clicking on the μ node, giving this Hinton diagram:
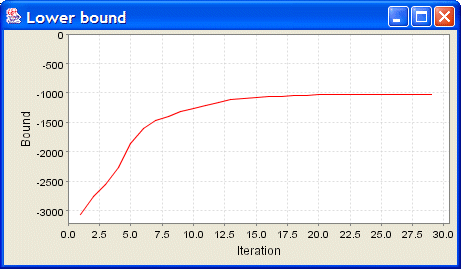
These learned means correspond to the centres of each of the data clusters. A graph of the evolution of the bound (shown below) can be displayed by clicking on the bound value. The converged lower bound of this new model is -1019 nats, which is significantly higher than that of the single Gaussian model, showing that there is much greater evidence for this model. This is unsurprising since a mixture of 20 Gaussians has significantly more parameters than a single Gaussian and hence can give a much closer fit to the data. Note, however, that the model automatically chooses only to exploit 9 of these components, with the remainder being suppressed (by virtue of their mixing coefficients going to zero). This provides an elegant example of automatic model complexity selection within a Bayesian setting.
|
|||