VIBES
Variational Inference for Bayesian Networks
[Sourceforge project page]
John Winn, January 2004
|
VIBESVariational Inference for Bayesian Networks |
[Sourceforge project page] John Winn, January 2004 |
| Overview | Tutorial | Examples | Help |
 Contents
Contents

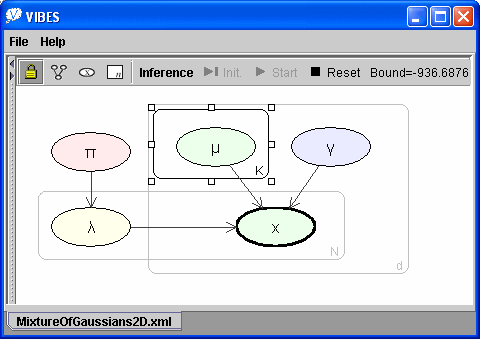
6. Modifying the mixture modelThe rapidity with which models can be constructed using VIBES allows new models to be quickly developed and compared. For example, we can take our existing mixture of Gaussians model and modify it to try and find a more probable model. Firstly, we may hypothesise that the each of the clusters have similar size and so that they may be modelled by a mixture of Gaussian components with a common variance in each dimension. Graphically, this corresponds to shrinking the K plate so that it no longer contains the γ node,like this:
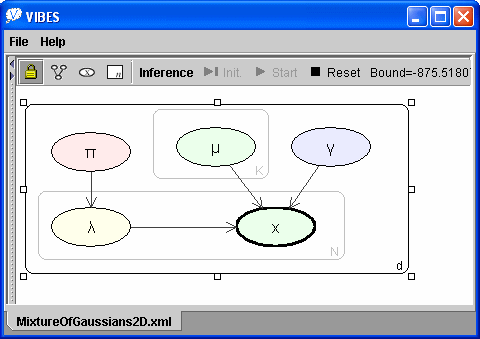
The converged lower bound for this new model is -937 nats showing that this modified model is better at explaining this data set than the standard mixture of Gaussians model. Note that the increase in model probability does not arise from an improved fit to the data, since this model and the previous one both contain 20 Gaussian components and in both cases 9 of these components contribute to the data fit. Rather, the constrained model having a single variance parameter can achieve almost as good a data fit as the unconstrained model yet with far fewer parameters. Since a Bayesian approach automatically penalises complexity, the simpler (constrained) model has the higher probability as indicated by the higher value for the variational lower bound. We may further hypothesise that the data set is separable with respect to its two dimensions (i.e. the two dimensions are independent). Graphically this consists of moving all nodes inside the d plate (so we effectively have two copies of a one-dimensional mixture of Gaussians model with common variance). To speed convergence, we also reduce the number of mixture components K to 5 - which will allow up to 25 2D clusters. A VIBES screenshot of this further modification is below.
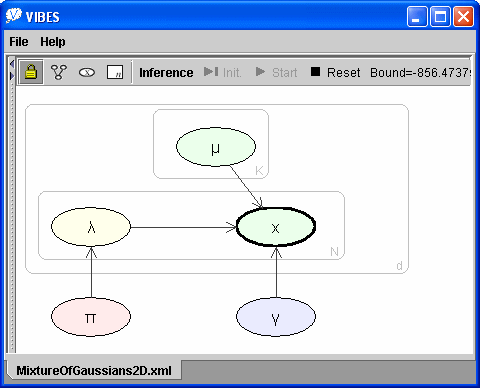
Performing variational inference on this separable model leads to each one-dimensional mixture having three retained mixture components and gives an improved bound of -876 nats. We will consider one final model. In this model both the π and the γ nodes are common to both data dimensions, as shown below. This change corresponds to the assumption that the mixture coefficients are the same for each of the two mixtures and that the component variances are the same for all components in both mixtures. Inference leads to a final improved bound of -856 nats.
|
|||